Planning a Search Engine
Building a search engine from scratch for fun and... expense?
By Abi KP
2022-06-12
6 minutes reading time
I've decided that one of my summer projects will be to build a search engine and accompanying crawler/spider (I'll end up calling it both from time to time) from scratch, because I feel like it, while also turning it into a series of posts on this blog.
This specific post is going to be dedicated to planning the project out - defining the components, the architecture, the database schemas, and some other stuff.
But first - we need a name, because the name is the most important part of the project![citation needed] I'm calling my search engine Surchable, which I lifted from an Amazon Original series called Undone. In S1E6, one of the characters, San, is using a search engine called... Surchable! I stole the name.
Project aims #
As part of this project, I want to:
- build a search engine for the non-commercial internet, much like search.marginalia.nu.1
- learn some stuff about various web standards (eg: robots.txt files, proper user agent formatting, database design, etc)
- have some fun
- end up with a somewhat-usable product at the end that people might actually use
Accordingly, there's also some anti-aims. I don't want to:
- piss anyone off (this means I must respect robots.txt files,
Cache-Controlheaders, ratelimiting and the like) - do extra work (try and coordinate things neatly between synchronous workers so I'm not re-indexing the same content over and over without due need)
- create a mindlessly slow piece of software (it's not going to be blazingly fast, but I'd like it to be decently quick)
High-level architecture #
There's going to be three main components to Surchable.
- The crawlers
- The coordinator
- The web UI
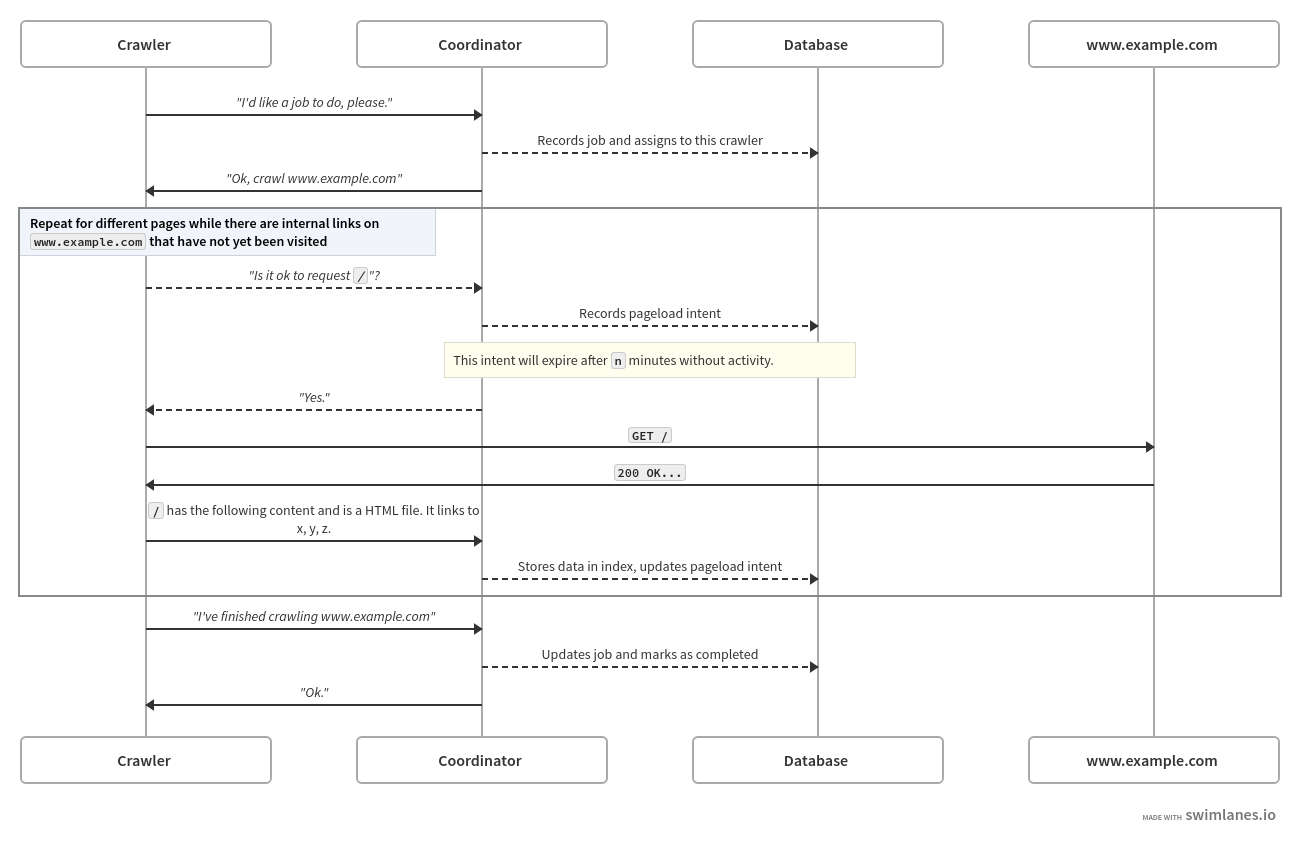
Let's start with the crawlers, of which we'll run multiple instances of at the same time.
The job of the crawlers will be to take "jobs" from the coordinator
and execute them. A job will be to go to a specific (sub)domain and make
some observations about each HTML page on it2 - where it links to, how large the page is, if it uses JavaScript, what it says, etc, etc. It'll do this by first loading the /
route (or another starting point specified by the coordinator),
scanning that for hyperlinks and collecting data about that page, then
scanning all other pages it can find based on those hyperlinks by
repeating the same process.
Before it requests any page, it'll check in with the coordinator to make sure that this page hasn't been scanned recently to avoid hammering a given site.
After every page load, the crawler will submit information about a page to the coordinator. When the entire job is finished, the crawler will tell that to the coordinator too, and then move on to processing another job.
But what happens if the crawler crashes mid-way through a job? If we
add a rule to the coordinator to say that any in-progress job should see
the crawler that's working on it check-in at least once every x
minutes, and a crawler doesn't fufil this, we assume the crawler's gone
offline for some reason and release the job to be assigned to another
crawler.
The coordinator itself will be the thing building and updating the master search index and page metadata tables, as well as managing job coordination, as mentioned earlier. Without going into huge detail about its inner workings, there's not a lot to say about it.
You can kinda see the whole process that we talk about above in this Swimlanes diagram.
Finally, the web UI. This is the only thing a user can see and interact with - it will allow someone to input a queryand get a list of results out and submit a URL for scanning. It'll have to perform result ranking, which (at least, for now) I plan to do using a combination of a relevancy filter and a bastardised version of the PageRank algorithm that was (is?) used by Google.3
The relevancy stuff is going to be done with some fancy maths involving frequencies and logarithms that I'll go into in more detail in the future.
The tech stack #
I've heard Golang called "the programming language for the internet" - it excels when used for writing networking or web applications, and for that reason it's going to be my primary language for this project. It'll be used to build the server for the web UI and the coordinator. This also allows core libraries, like the database access libraries, to be easily shared across the different applications that make up the search engine.
The actual crawlers will be implemented in Python, due to the maturity of libraries like BeautifulSoup and Selenium or Playwright for Python.4 I'm not yet decided if I want to use instances of headless Chrome and similar for the scrapers yet, or if I want to just request plain HTML and process that. I'm leaning towards the latter since it's considerably simpler and since it shouldn't matter if we don't have JS support for what we're doing, but we'll have to wait and see.
The database will be built around a database server, likely PostgreSQL. Typically, I'd use a single-file database, such as SQLite3, but this isn't feasable when both the web UI and the coordinator will be accessing the same database at the same time.
The web UI will be built from scratch as a set of HTML and (S)CSS pages that are rendered on the server then sent to a user's browser. I very briefly considered using Svelte for the front-end, but I'd much prefer to keep things as simple and as light-weight as possible. If I want to add some SPA-style interactions into the frontend, I'll use HTMX, which is a super, super cool JavaScript library that enables HTML to be sent over-the-wire and inserted into the currently loaded page, all configured via attributes on HTML elements. As a plus, it's also fairly small.
The series #
I plan to make a series of ~4 blog posts about Surchable, this one included. Development won't be starting for a couple of weeks yet due to real-life goings on, but this is going to be my summer project. I have both an Atom feed and a JSON feed if you want to subscribe for future posts. If you've got any questions at the moment, send me a friend request on Discord (check my homepage for details) and I'll be more than happy to chat with you.
Footnotes #
- I think a pretty easy way to do this is to check and see if a page has ads on it or not, if so, excluding it from the index and not crawling any pages it links to. ↝
- And maybe plain text files too, since they should be pretty simple to tokenise and throw into the database. More information about tokenising and the database table structure coming later on! Promise. ↝
- https://en.wikipedia.org/wiki/PageRank#Algorithm ↝
- While yes, there are alternatives to both of these for Go, they're a little more clunky than the Python versions. I've also done large-scale web-scraping projects in Python before now. ↝